
The goal of this chapter is to understand correlation analysis and regression analysis and the difference between them.
Correlation analysis assesses the occurring variability of a collection of variables. Thus, this type of relationship is not directional and our interest is not on how some variables respond to others, but to examine how the variables are mutually associated. In comparison, regression analysis is used when you want to identify the relationship between a dependent variable and one or more independent variables.
Some confusion may occur between correlation analysis and regression analysis. Both analyses often refer to the examination of the relationship that exists between two variables, x and y, in the case where each particular value of x is paired with one particular value of y. The difference is that regression analysis is a statistical technique that allows the scientist to examine the existence and extent of this relationship. Correlation analysis determines the strength of the relationship between variables.
We start by looking at the correlation coefficient, more specifically, the Pearson sample correlation coefficient which is between two variables with three different conditions, as discussed in Chapter 6.
The Pearson sample correlation coefficient, often referred to as Pearson’s r, is a measure of the linear correlation (dependence) between two variables x and y, given a value between +1 and −1 inclusive, where 1 is total positive correlation, 0 is no correlation, and −1 is total negative correlation.
Pearson’s r is a numerical measurement that assesses the strength of a linear relationship between two variables x and y.
Its rules are:
1. r is a unitless measurement between –1 and 1. In symbols, –1 ≤ r ≤ 1. If r =1, there is positive linear correlation. If r = 0, there is no linear correlation. The closer r is to 1 or –1, the better a line describes the relationship between the two variables x and y.
2. Positive values of r imply that as x increases, y tends to increase. Negative values of r imply that as x increases, y tends to decrease.
3. The value of r is the same regardless of which variable is the explanatory variable and which is the response variable. In other words, the value of r is the same for the pair (x, y) and the corresponding pair (y, x).
4. The value of r does not change when either variable is converted to different units.
There are several formulas that can be used to compute Pearson’s r. Some formulas make more conceptual sense, whereas others are easier to actually compute. We begin with a conceptual formula. The computation conceptual formula for r:
r = Σ (xy) / sqrt [ ( Σ x2 ) * ( Σ y2 ) ]
where Σ is the summation symbol, x = xi – x, xi is the x value for observation i, x is the mean x value, y = yi – y, yi is the y value for observation i, and y is the mean y value.
Example:
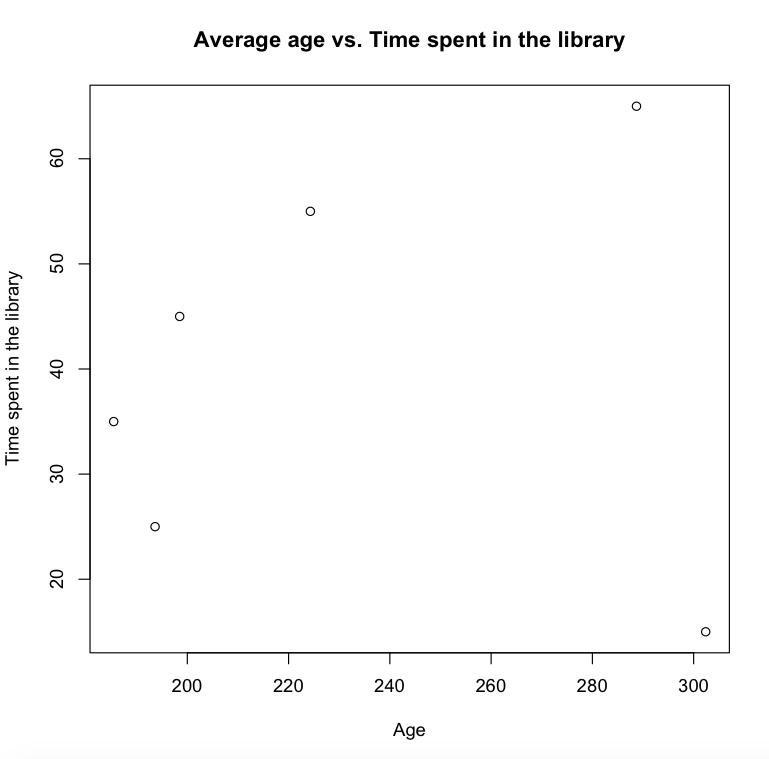
We looked at a recent report that measured the average age of users visiting the library versus time spent in the library by those users in Austin, TX.
| Age group | Representative age | Hours spend in the local library |
|---|---|---|
| 10-19 | 15 | 302.38 |
| 20-29 | 25 | 193.63 |
| 30-39 | 35 | 185.46 |
| 40-49 | 45 | 198.49 |
| 50-59 | 55 | 224.30 |
| 60-69 | 65 | 288.71 |
In order to illustrate the relationship between the average age versus the time spent in the library, we created a scatterplot.
The code in R:
>x <- c(302.38, 193.63, 185.46, 198.49, 224.30, 288.71)
>y <-c(15, 25, 35, 45, 55,65)
>plot(x,y, main=”Average age vs. time spent in the library”, xlab=”Age”, ylab=”time spent in the library”)
Result:
The Pearson product-moment correlation coefficient test
As discussed above, regression analysis is a statistical process for estimating the relationships among variables. It includes many techniques for modeling and analyzing several variables, when the focus is on the relationship between a dependent variable and one or more independent variables (or ‘predictors’). We will look at the Pearson product-moment correlation coefficent test as form of regression analysis.
The Pearson product-moment correlation coefficient test is the measure of the strength of the linear relationship between two variables and value of Pearson’s r. The aim is to draw a line for the best fit through the data of the two variables. The value of r indicates the distance of the data points from the line of best fit (how well the data points fit this new model/line of best fit). The symbol “p” represents population and r represented the sample. In order to scale the result, we measure the value of r between -1 and +1, as illustrated below. A value near the upper limit, +1 indicates a strong positive relationship, whereas an r closer to the lower -1 suggests a strong negative relationship. When a score of r is equal 0, it indicates that there is no relationship between variables.
The Pearson product-moment correlation coefficient does not take into consideration whether a variable has been classified as a dependent or independent variable. It treats all variables equally. The properties of the value of r do not depend on the unit of measurement for either variables (Average age vs. time spent in library). We often incorporate the score of Z to measure the product moment correlation coefficient of the two variables.
In R the Pearson product-moment correlation coefficient test code consists of:
> cor.test(x, y, method = “pearson”)
data: x and y
t = 0.077, df = 4, p-value = 0.9423
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.7980031 0.8242983
sample estimates:
cor 0.03847689
In this example our data shows a weak relationship between age and time spent in the library.
Next, Chapter 13, Analysis of Variances and and Chi-Square Test
Previous, Chapter 11, Fundamentals of Hypothesis Testing